
Can you beat the machine?
This project creates an agent that learns how to play Tic-Tac-Toe by itself. The agent is based on a simple neural network with 2 fully connected hidden layers. I didn’t play around with the network architecture too much since Tic-Tac-Toe has a low skill ceiling and the agent was sufficiently good.
A few things I approached differently from the original kernel was how the board state is represented and having the agent play against itself. For the board state, I changed player 1, player 2, and empty state from 1, 2, 3 to 1, -1, and 0, respectively. I thought it made more sense for the empty state to be in between the two players compared to 0, 1, 2. This turned out quite well for training. Initially, the agent was making poor moves even after 200K games played. With this representation, performance was much better with only 100K games.
The training was done in groups of 250 games over 400 rounds for a total of 100K games. During a round, the agent will play against itself by alternating between the move with the highest expected score and then the move with the lowest expected score (1 for Player 1 win, 0.5 for draw, 0 for Player 2 win). To help the agent explore different options, it has a 20% chance of picking a random move. Every board state of each game will be updated with the final score and added to the training data. At the end of each round, the model will use the accumulated training data to update its weights.
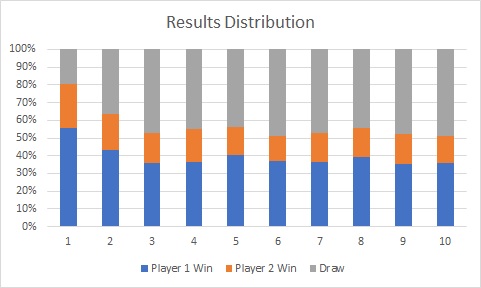
Each bar in the chart represents 10K games played. You can see that going first was a significant advantage in the beginning but the results start to stabilize after 30K games. It will be interesting to test the strength of the agent at various points.
So how does it perform? Pretty well. Generally, I could not beat the agent when it moved based on highest expected score. There were some edge cases that led to silly losses - I will leave it for you to find them. Sometimes a losing move would have an expected score that's within 0.01 of the winning move but as they say, it doesn't matter if you win by an inch or a mile. Winning is winning!
Source code is available on Github. This project was inspired by this Kaggle kernel.